

Cracking non-English character passwords using Hashcat

André Ahlfors Dahl
Cybersecurity Consultant
Background
In the line of my work as a penetration tester, I get the opportunity to test the security of a lot of different customer systems.
What they all have in common is that they all have users - and users tend to have passwords in some variants.
When we test the security of a network, we often achieve access to hashed credentials of users of that organization.
But getting the hashes is only half the fun.
The other part is to make something usable of the hashes by cracking them and get the passwords in clear text.
With this information, we can make some analysis and recommendations for the customer.
People in Europe tend to use passwords that include the local language special characters.
These characters are slightly different from the normal ASCII table and a bit trickier for a password cracking application like Hashcat to understand.
In this article, I describe how to create mask files for Hashcat with a UTF-8 multibyte character set.
Character encoding
ASCII is the original character encoding schema for Latin/English characters.
It consists of 128 characters/symbols which are encoded from 0000 0000 to 0111 1111 in binary.
A single byte can only encode 256 values, but this is often not enough. To encode all possible characters we must use several bytes, much like we can encode numbers bigger than 9 using several digits.
One such way to encode characters and symbols is the UTF-8 encoding.
It uses one to four bytes (from 0000 0000 to 1111 0111 1011 1111 1011 1111 1011 1111) and was designed to be backward compatible with ASCII.
The first 128 bit combinations (from 0000 0000 to 0111 1111) are reserved for the ASCII characters.
(In other words, ASCII and the first 128 characters in UTF-8 have a direct one-to-one mapping).
This gives us the same encoded byte values for the same character no matter if we use ASCII or UTF-8.
The bytes is what matters since this is what Hashcat uses.
To understand this better, let us compare the UTF-8 table and the ASCII table with each other.
(Ideally, open the pages side by side.)
If we select hex as the display format on the UTF-8 page we can see that all ASCII characters are represented in the same way as in the ASCII table.
If we look further down the UTF-8 table we can see where the ASCII set ends and other characters start.
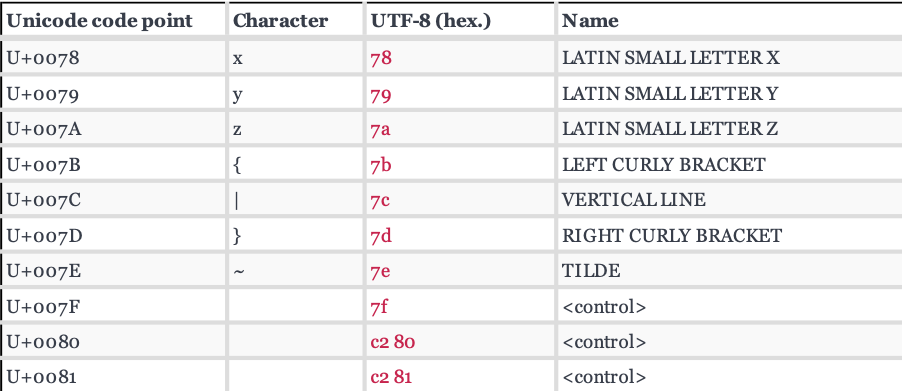
Looking at the hex value we can see that after 7f we need two bytes to encode a single character.
The first byte is called base code and the second byte is called character code.
As an example, we look at the germanic characters åäö. They are found a bit further down in the UTF-8 table:

The character ä is encoded as c3 a4 in UTF-8.
This means c3 is the base code and a4 is the character code.
This is important because it is the format Hashcat understands.
Hashcat
So what support does Hashcat offer for non-ASCII characters?
At the help page (hashcat --help) we can read about the option that will do the heavy lifting for us: --hex-charset.
The description of that command says “Assume charset is given in hex”.
Armed with this information and a UTF-8 table we can now start tinkering with some examples.
Basic test file
First we create some passwords with our local characters and pipe them through md5sum to get them hashed.

Hashcat mask attack
With some examples ready to crack we fire up Hashcat with a mask attack on our hashes but also let Hashcat know that we want it to use our own custom set character set.
./hashcat --potfile-disable -m 0 -a 3 md5_test.txt --hex-charset -1 c3 -2 a4a5b6 ?1?2?a?a
Lets break it down:
- --potfile-disable means that the cracked passwords will not be saved in the potfile.
- -m 0 hashtype setting, 0 for MD5 hashes
- -a 3 attacktype setting, 3 for bruteforce
- md5_test.txt is our file containing the hashes.
- --hex-charset tells Hashcat to interpret our custom characters sets as hex.
- -1 c3 means “use custom character set” but only with our base code c3.
- -2 a4a5b6 “use second custom character set” set to character codes a4 a5 b6.
- ?1?2?a?a is our Hashcat mask.
What Hashcat will do is that it will combine ?1?2 into c3a4, c3a5 and c3b6 wich are the bytes that encode the characters äåö. The two ?a denotes a Hashcat standard character set.
The problem with this attack is that it will only crack the password if it is exactly three characters long and only the first letter starts with our custom character. To capture all variants we need to approach this in a more generic way. Enter maskfiles.
Maskfiles
To reduce the number of arguments to Hashcat and make things structured, we use maskfiles.
A maskfile is a plaintext file formatted according to the Hashcat manual.
[Cust charset 1, [Cust charset 2, [Cust charset 3, [Cust charset 4,]]]] MASK
The custom charsets are optional, but in our case we do want to use two of them. One for the base code and one for the character codes.
A mask file with the same properties as our previous example would look like this:
c3,a4a5b6,?1?2?a?a
We save that in a file called custom_mask.hcmask and load it up in Hashcat:
./hashcat --potfile-disable -m 0 -a 3 md5_test.txt --hex-charset custom_mask.hcmask
To generate your own maskfiles you probably want to check out the policygen from PACT toolkit.
A quick way to generate a maskfile for all 3 character password candidates is:
python policygen.py --minlength 3 --maxlength 3 --mindigit 0 --minlower 1 --maxupper 0 --maxspecial 0 -o /path/to/file/8charUTF8.hcmask
The output needs to be edited with a regexp or search-and-replace to achieve the desired result. Replace l with 1?2 and d with a to achieve bruteforce like coverage including your special characters in all positions.
Conclusion
My intention with this solution is to crack hashes with letters from contemporary Germanic languages, but it can be used for any non-English UTF-8 characters with some adjustment.
Happy cracking!
Some great resources covering more about this subject